英文:Fine-tuning 中文:大模型微调
大模型的构建其实分为 2 个阶段:
- 预训练(pre-training):此阶段模型会在 大规模、多样化的数据集 上进行训练,从而形成全面的语言理解能力。
- 微调(fine-tuning):在规模较小的 特定任务或特定领域数据集 上对模型进行 针对性的训练。
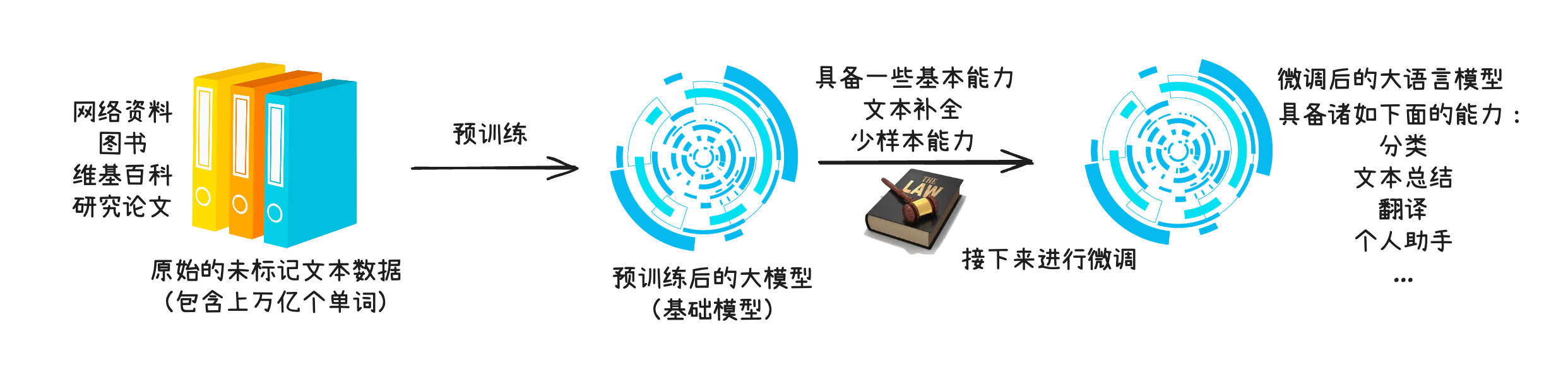
- 预训练:通才,什么都懂一点
- 微调:某领域专家
微调 和 提示词工程、RAG 之间的区别:
| 项目 | 微调(Fine-tuning) | 提示词工程(Prompt Engineering) | RAG(检索增强生成) |
|---|---|---|---|
| 定义 | 基于已有模型,用新数据“训练”一遍以适应特定任务 | 通过设计更优提示词,提高模型表现 | 在生成前引入“外部知识”作为上下文供模型参考 |
| 是否改动模型参数 | ✅ 会,训练会更新模型权重 | ❌ 不会,只用原始模型 | ❌ 不会,主要改进数据流 |
| 适用场景 | 高精度、专属领域(如医疗、法律) | 通用模型适配多任务、快速试验 | 数据频繁更新、文档 QA、知识密集型任务 |
| 依赖外部数据源 | 需要少量高质量训练数据 | 可选,通常仅靠提示 | 必须,需要知识库或文档 |
| 部署复杂度 | 较高,需要训练和模型部署 | 最低,只依赖提示词 | 中等,需接入检索系统(如向量库) |
大模型微调分类#
可以从不同的维度分类:
- 技术维度
- 任务维度
技术维度#
- 全量微调(Full Fine-tuning)
- 参数高效微调(PEFT,Parameter-Efficient Fine-tuning)
全量微调
对模型的 所有参数 进行更新,而不是只更新其中的一小部分。
全量微调的特点如下:
| 方面 | 内容 |
|---|---|
| 所需数据 | 几万到几百万条的任务数据,且更专注(例如医学),并且是高质量的数据 |
| 参数更新 | 模型所有参数(数十亿)都更新 |
| 显存要求 | 高(通常 40GB+,分布式训练) |
| 收敛速度 | 慢(通常需要数天训练) |
🤔全量微调是否就和预训练相同?
不一样
| 维度 | 预训练 | 全量微调 |
|---|---|---|
| 数据 | 万亿 token、网络通用语料(Wikipedia、书籍、网页) | 小规模任务数据(几万 ~ 几百万条),且更专注(如医学) |
| 目标 | 让模型“学会语言”本身(通用语言知识) | 让模型“适配任务”或“专精领域” |
| 耗时 | 数周到数月 | 通常几小时到几天 |
| 模型规模 | 从 0 开始构建参数 | 以已有模型为初始参数进行继续优化 |
参数高效微调
指的是只训练少量参数或添加轻量模块。
常见参数高效微调方法:
- LoRA(Low-Rank Adaptation):插入低秩矩阵来替代直接更新大模型参数
- Prefix Tuning:为每个输入添加一小段可训练的“前缀”向量
- Adapter Tuning:在 Transformer 层之间插入小模块
- QLoRA:LoRA + 量化(Quantization)
以 LoRA 这种参数高效微调为例,和全量微调做一个对比:
| 对比项 | 全量微调 | LoRA 微调 |
|---|---|---|
| 训练参数量 | 所有参数(数十亿) | 百万级(几乎只改插入模块) |
| 训练显存 | 极高 | 中低(8~24G 可跑) |
| 通用性 | 全面改造 | 仅适用于因任务略微变化 |
| 训练速度 | 慢 | 快得多 |
| 适合初学者 | (难度高) | 简单易用 |
任务维度#
- 指令微调(Instruction Fine-tuning)
- 分类任务微调(Classification Fine-tuning)
两者的区别主要是在 输出方面。
指令微调
生成完整自然语言回答,开放式文本
{ "instruction": "请判断患者是否存在糖尿病风险,并说明依据。", "input": "患者男,45岁,BMI指数29,空腹血糖6.8 mmol/L。", "output": "患者可能存在糖尿病前期的风险,建议进一步做 OGTT 检查。"}指令微调就像是你教模型做开放性问答题或写作题。
- 输入:题目要求和背景材料
- 输出:一段自然语言分析、论述或建议。
分类任务微调
一般输出标签、数字、选项,结构化值
{ "text": "患者男,45岁,BMI指数29,空腹血糖6.8 mmol/L。", "label": "糖尿病前期"}分类任务微调则是像你教学生做选择题或判断题。
- 输入:一段信息
- 输出:正确选项是 A、B、C 或 “阳性”、“阴性”。
-EOF-