RAG经典架构:
数据索引
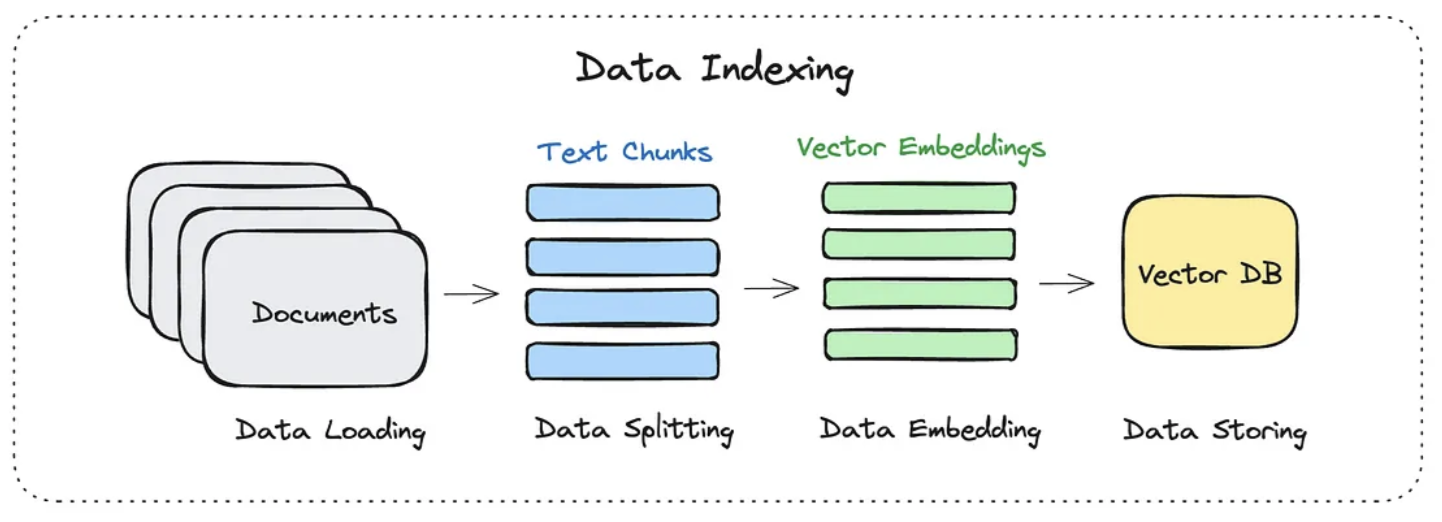
读取外挂语料库的时候,语料库是一个 pdf 文件,需要一个额外的依赖:pdf-parse
转化为向量嵌入:nomic-embed-text
function getEmbedding(text) { const res = await fetch("http://localhost:11434/api/embeddings", { method: "POST", headers: { "Content-Type": "application/json" }, body: JSON.stringify({ model: "nomic-embed-text", prompt: text, }), }); const result = await res.json(); return result.embedding;}本节课的实践会用到两个模型:
- 在线的 deepseek
- 本地模型 nomic-embed-text 用来做向量嵌入
数据查询
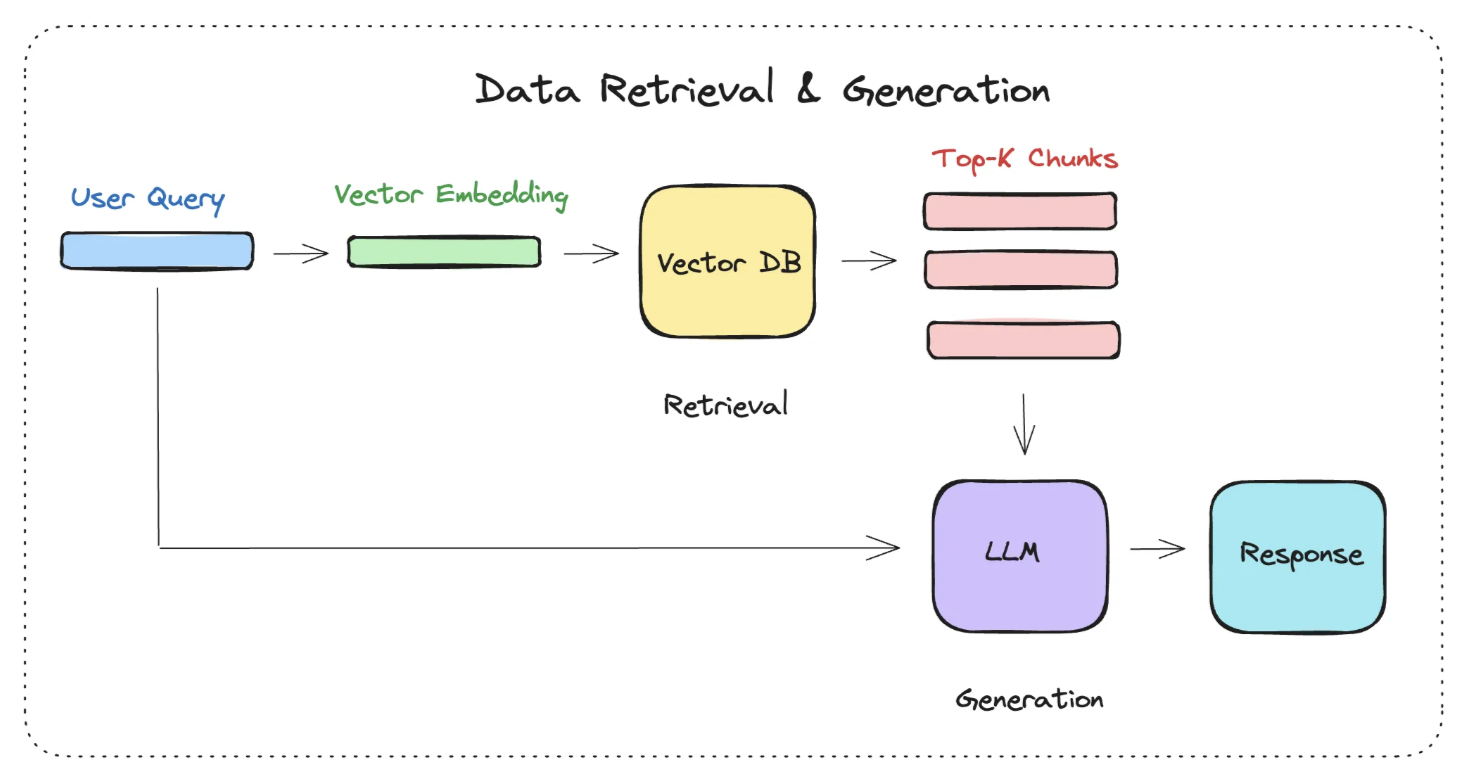
余弦相似度计算
/** * 余弦相似度计算 * @param {*} vecA * @param {*} vecB * @returns */function cosineSimilarity(vecA, vecB) { const dot = vecA.reduce((sum, val, i) => sum + val * vecB[i], 0) const normA = Math.sqrt(vecA.reduce((sum, val) => sum + val * val, 0)) const normB = Math.sqrt(vecB.reduce((sum, val) => sum + val * val, 0)) return dot / (normA * normB)}根据阀值判断是否使用外挂知识库
let userMessage = question
// 严格判断:要求所有文档的得分都大于阈值const allDocsRelevant = relevantDocs.length > 0 && relevantDocs.every((doc) => doc.score > RELEVANCE_THRESHOLD)
if (allDocsRelevant) { console.log(`✅ 知识库相关 - 所有文档得分都超过阈值 ${RELEVANCE_THRESHOLD}`) console.log( ` 文档得分: [${relevantDocs .map((doc) => doc.score.toFixed(3)) .join(', ')}]` )
// 将相关的知识库内容添加到用户问题中 const relevantContent = relevantDocs .filter((doc) => doc.score > RELEVANCE_THRESHOLD) .map((doc) => doc.content) .join('\n\n')
userMessage = `参考以下资料回答问题:
${relevantContent}
问题:${question}`} else { const failedDocs = relevantDocs.filter( (doc) => doc.score <= RELEVANCE_THRESHOLD ) console.log(`❌ 知识库不相关 - 有${failedDocs.length}个文档得分不足`) console.log( ` 文档得分: [${relevantDocs .map((doc) => doc.score.toFixed(3)) .join(', ')}]` ) console.log(` 阈值要求: ${RELEVANCE_THRESHOLD}`)}