基本介绍#
RAG,全称 Retrieval-Augmented Generation,中文:检索增强生成
核心思想:为大模型补充来自于外部的相关数据与上下文,从而帮助大模型生成更丰富、更准确、更可靠的内容。
也就是临时给大模型外挂一个知识库。
解决的问题:
- 受限于已有知识库,无法快速新增语料信息
- 重新训练大模型需要很长的时间
案例
假如你需要开发一个在线的自助产品咨询工具,允许客户使用自然语言进行交互式的产品问答。
假设我们的产品是:香蕉手机
请介绍一下您公司这款产品(香蕉手机)与XX产品的不同之处为了让客户有更好的体验,我们决定使用大模型来构造这样的咨询功能并将其嵌入到公司的官方网站。
如果你直接使用通用大模型,那么结果可能如下:

现在,假设我们使用 RAG 外挂知识库,就需要先补充一段公司产品的信息,例如:
香蕉手机 Pro(定位:时尚复古轻旗舰)
| 参数项 | 配置说明 |
|---|---|
| 外观设计 | 弯曲滑盖造型(致敬诺基亚8110)铝合金中框 + 聚碳酸酯背板可选复古黄 / 银灰 / 磨砂黑 |
| 屏幕 | 5.9 英寸 AMOLED,FHD+(2400x1080)窄边框设计,支持Always-On显示 |
| 处理器 | Qualcomm Snapdragon 7 Gen 3 |
| 内存与存储 | 8GB + 128GB / 8GB + 256GB |
| 操作系统 | 定制版 Android 14(香蕉OS UI) |
| 主摄像头 | 50MP 主摄(Sony IMX766)f/1.8,OIS光学防抖 |
| 前置摄像头 | 16MP 居中打孔摄像头 |
| 电池容量 | 4200mAh,支持 33W 快充(USB-C) |
| 特色功能 | 滑盖可接听 / 挂断电话实体功能键支持自定义(可设置为快捷启动相机、支付等) |
| 连接性 | 5G / WiFi 6 / 蓝牙 5.3 / NFC / eSIM |
| 重量 | 185g |
| 售价预估 | ¥2699 起 |
香蕉手机 Ultra(定位:旗舰全能机)
| 参数项 | 配置说明 |
|---|---|
| 外观设计 | 同样采用滑盖香蕉造型 + 陶瓷背板钛合金中框,IP68 防尘防水 |
| 屏幕 | 6.78 英寸 AMOLED,3200x1440(2K)120Hz LTPO 自适应刷新率,HDR10+ |
| 处理器 | Snapdragon 8 Gen 3 |
| 内存与存储 | 12GB + 256GB / 16GB + 512GB / 1TB UFS 4.0 |
| 操作系统 | Android 14(香蕉OS Pro) |
| 影像系统 | 三摄组合:主摄:50MP (IMX989 1英寸传感器)超广角:48MP潜望式长焦:64MP 5X 光学变焦 |
| 前置摄像头 | 32MP 居中打孔 |
| 电池容量 | 5000mAh,支持 100W 有线快充 + 50W 无线快充 |
| 特色功能 | 滑盖自定义为快捷相机 / 支付 / 截图AI助手:滑盖触发语音助手指纹识别 + 人脸识别双生验证 |
| 连接性 | 5G / WiFi 7 / 蓝牙 5.4 / NFC / 双eSIM / UWB |
| 重量 | 205g |
| 售价预估 | ¥5999 起 |
接下来我们将这段补充知识作为提示词的一部分,将其输入到大模型中,并要求大模型基于提供的知识来回答问题:

得到的答案如下:

可以看到,大模型很聪明的吸收了补充的外部知识,并结合自己已经掌握的知识,成功的推理并给出了答案。
经典架构#
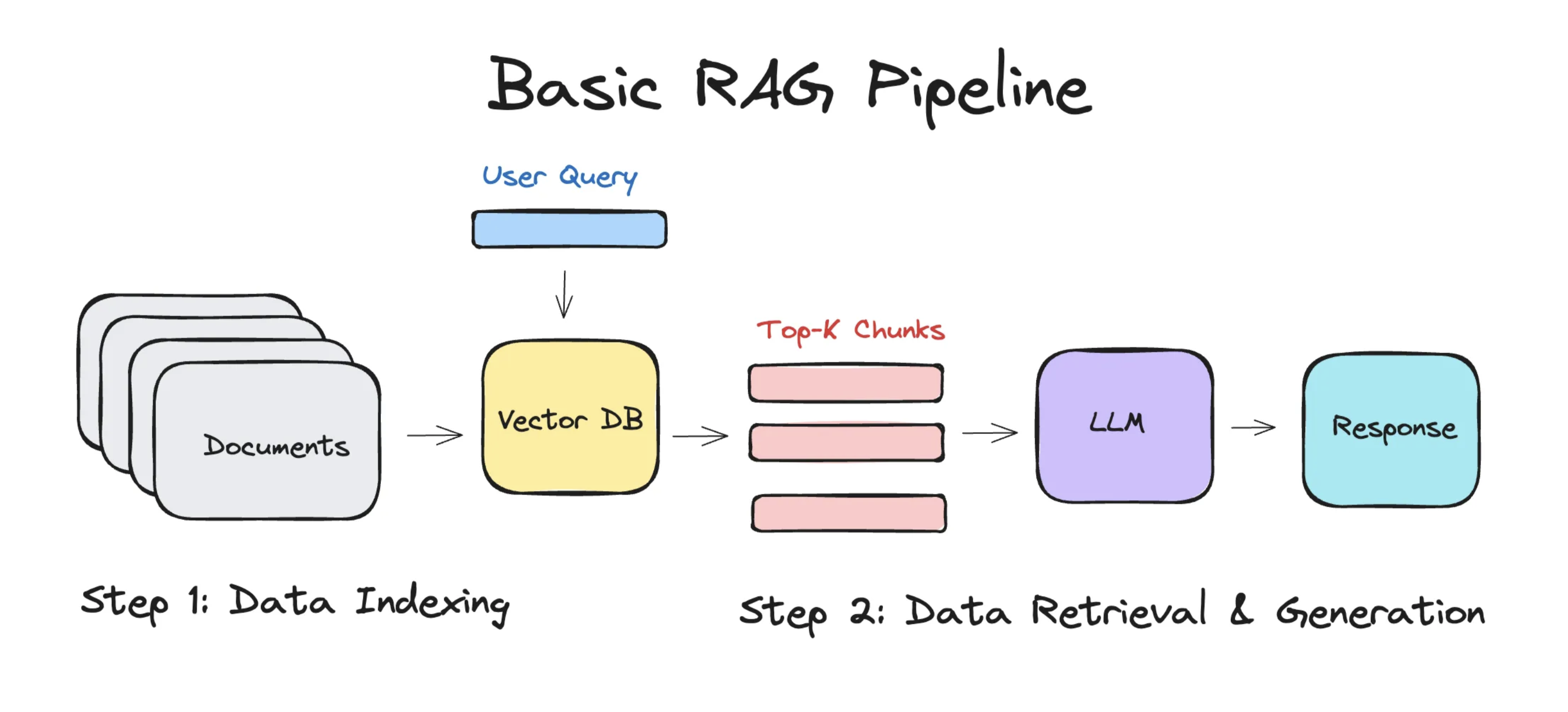
简单的 RAG 应用从整体上分为两个阶段:
- 数据索引(Data Indexing)
- 数据查询(Query)
- 检索(Retrieval)
- 生成(Generation)
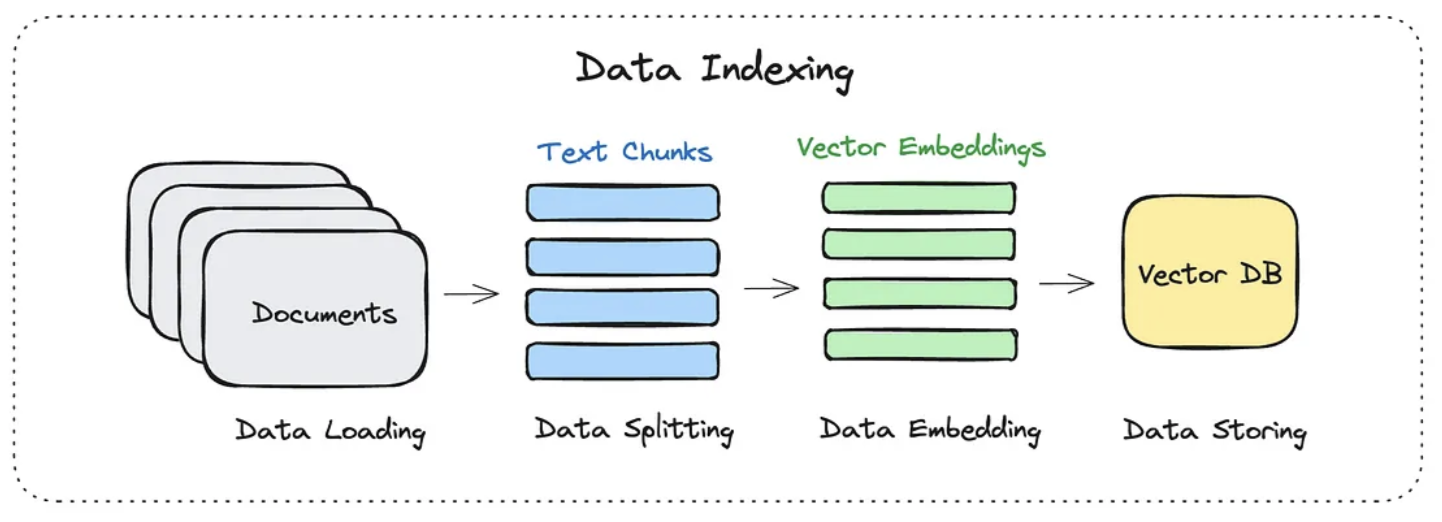
1. 数据索引#
在做数据索引时,通常分为这么几个步骤:
- 加载文档
- 切分成 chunks
- 转化为向量嵌入
- 存入向量数据库
切分成chunks
对输入的文档进行分割,分割成一个一个知识块(Chunk),从而为后续嵌入做准备。
-
语义结构维度:强调的是语义完整性,防止模型拿到“断句、不完整”的上下文。
可以按照句子的粒度进行切割,将每一段文本按句号、问号、叹号等 标点符号 分割。
原文:ChatGPT 是由 OpenAI 开发的大语言模型。它基于 Transformer 架构,具有强大的语言理解和生成能力。切割后:1. ChatGPT 是由 OpenAI 开发的大语言模型。2. 它基于 Transformer 架构,具有强大的语言理解和生成能力。 -
实现策略维度:满足向量模型有最大词元限制,比如 OpenAI embedding 最大约 8192 词元数。
- 固定长度字符切分:每 N 字符为一段,适合规则性较强的文档
- 词元切分:每 N 个词元切一段,兼容模型的词元数限制
上面这两个策略可以组合着来使用。
// langchain.js 里面的切割import { RecursiveCharacterTextSplitter } from 'langchain/text_splitter'
const splitter = new RecursiveCharacterTextSplitter({ chunkSize: 500, // 每段最多 500 字符 chunkOverlap: 100, // 相邻段重叠部分})
const docs = await splitter.createDocuments([text])转为向量
将每个 chunk 转换为一个“高维向量”,用来表达其语义。
每个向量通常是一个长度为 1536 或 768 的浮点数数组,例如:
[0.112, -0.045, 0.203, ..., 0.087] // 一个 chunk 的语义向量存入向量数据库
一般会存储在功能全面的 向量数据库 里面,向量数据库会提供强大的向量检索算法与管理接口,这样可以很方便地对输入问题进行 语义检索。
常见向量数据库:
| 向量库 | 特点 |
|---|---|
| Supabase | PostgreSQL + pgvector 扩展 |
| Weaviate | 云服务 + 本地部署均可 |
| Pinecone | 高性能、易接入 |
| Milvus | 海量数据、高性能搜索 |
| MemoryVectorStore | 纯 JS 内存向量库(测试用) |
2. 数据查询#
数据查询阶段的两大核心阶段是 检索 与 生成。
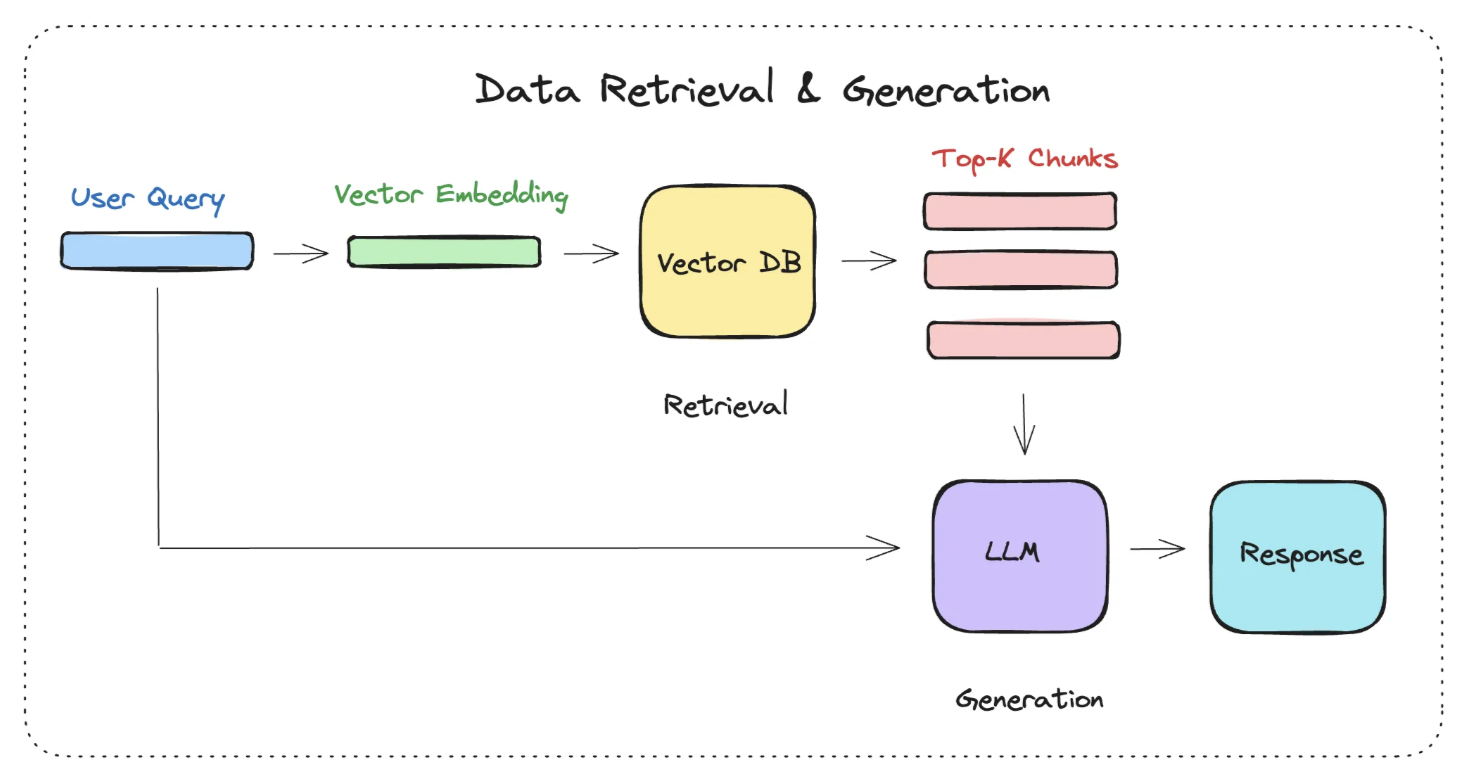
检索阶段
分为下面几个步骤:
-
将 Query(用户的问题) 转化为向量
-
在向量数据库中进行相似度检索,相似度的检索,有几种方式
- 余弦相似度
- 欧氏距离
- 点积
-
为生成阶段准备检索结果
生成阶段

构造出来的提示词大致如下:
[系统提示]:你是一个智能客服助手,请基于以下资料回答用户的问题。
[资料内容]:1. 本产品支持7天无理由退货。2. 如存在质量问题,可申请退换货。3. ...
[用户问题]:我买的这个产品坏了还能退吗?
[你的回答]:完整的流程
-EOF-